在人工智能领域,尽管现有的尖端大语言模型展现了强大的智能,能够在多项任务上匹敌甚至超越人类,但其庞大的参数规模带来的高昂成本一直是企业和开发者的痛点。这些模型,动辄拥有数千亿乃至万亿参数,训练、部署及推理费用不菲,对于处理简单却需要大规模和高并发任务的企业而言,可能并非性价比最优的选择。
针对这一现状,一家名为Fastino的初创公司应运而生,他们以低成本高效能为核心,利用低端游戏GPU,以不到10万美元的平均成本,打造出了一系列“任务特定语言模型”(TLMs)。这些小型模型在特定任务上的表现媲美大型语言模型,且推理速度提升了99倍。
近期,Fastino宣布获得由Khosla Ventures领投的1750万美元种子轮融资,Insight Partners、Valor Equity Partners以及知名天使投资人Scott Johnston和Lukas Biewald也参与其中。加上2024年11月由M12(微软旗下)和Insight Partners领投的700万美元前种子轮融资,Fastino累计融资已接近2500万美元。
Fastino由连续创业者Ash Lewis(CEO)和George Hurn-Maloney(COO)共同创立。Ash Lewis曾参与创立多家AI原生公司,拥有丰富的行业经验。公司还组建了一支由谷歌DeepMind、斯坦福大学、卡内基梅隆大学及苹果公司人才构成的技术团队,致力于从底层技术革新,开发出高效的任务特定语言模型。

在AI模型不断追求更大规模的背景下,Fastino反其道而行之,以低成本、高效率的TLM模型切入市场。这些模型不仅降低了运行成本,还解决了大尺寸模型在特定任务上性能不突出、推理速度慢的问题。Fastino的联合创始人George Hurn-Maloney表示:“AI开发者需要的不是泛化的大语言模型,而是适合其任务的精确模型。”
Fastino的TLM模型专为需要低延迟、高精度AI的应用场景设计,不追求通用性,而是针对特定任务进行优化。这些模型结合了Transformer的注意力机制,并在架构、预训练和后训练阶段引入任务专精,优先考虑紧凑性和硬件适应性,同时不牺牲任务准确性。因此,TLM模型能够在低端硬件上高效运行,对比OpenAI GPT-4o的4000ms延迟,TLM模型的延迟低至100ms,性能提升显著。
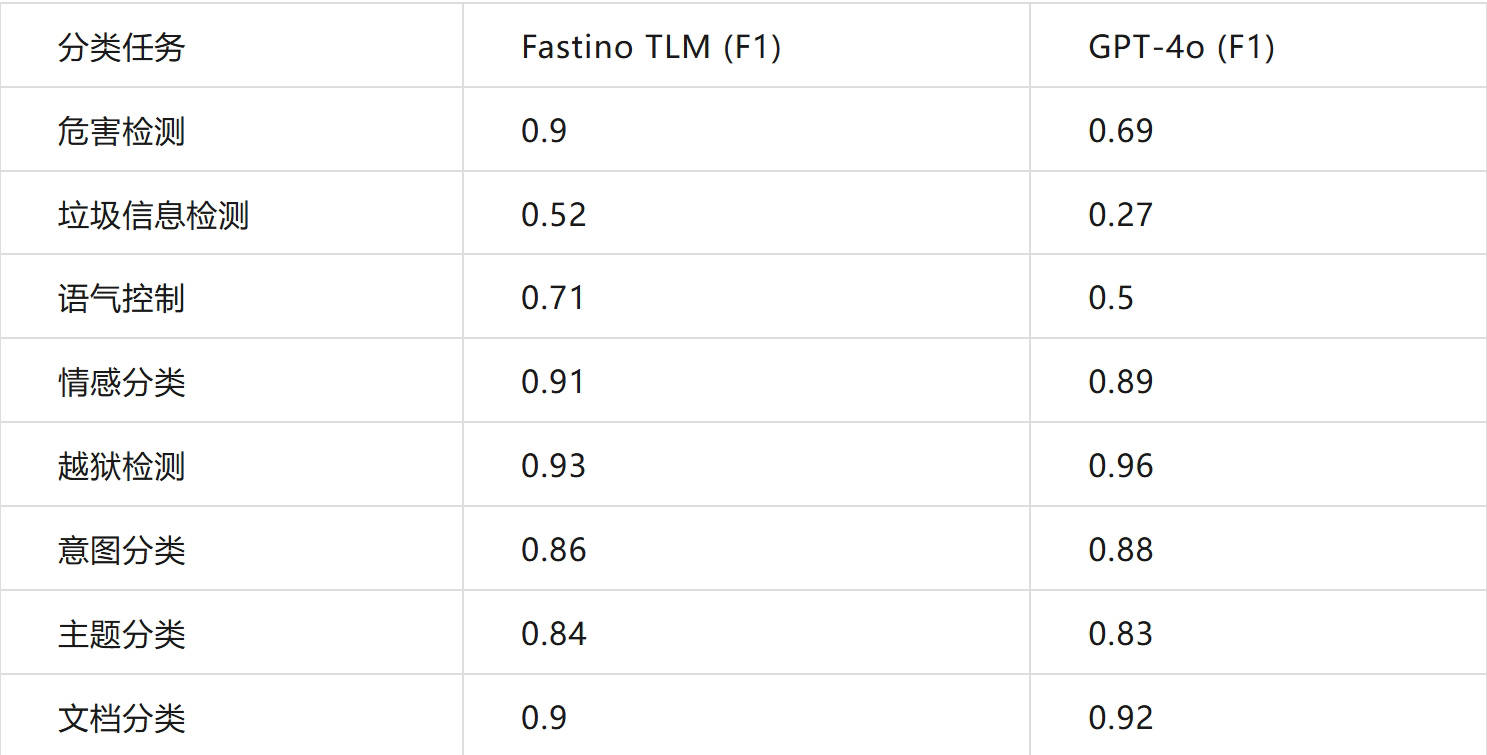
在性能测试中,Fastino的TLM模型在意图检测、垃圾信息过滤、情感倾向分析、有害言论过滤、主题分类等基准上,相较于GPT-4o表现出色,F1分数高出17%。TLM模型还具备文本摘要、函数调用、文本转JSON、PII屏蔽、文本分类、脏话过滤和信息提取等多种功能,适用于法律、医疗、电子商务等多个行业。
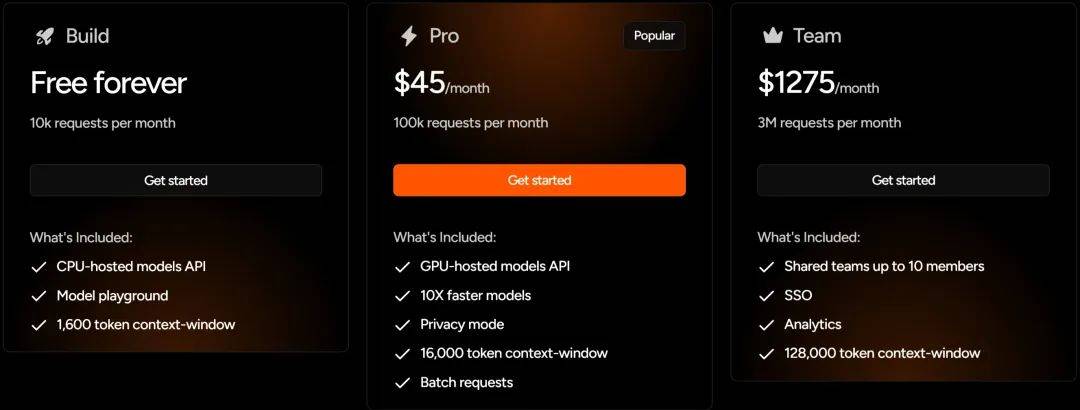
在收费模式上,Fastino采用了订阅制,对个人开发者提供每月1万次免费请求,Pro用户每月10万次请求仅需45美元,团队用户300万次请求每月1275美元。这种收费模式对初级开发者和中小企业较为友好,降低了AI应用的门槛。
Fastino的TLM模型还可部署在客户的虚拟私有云、本地数据中心或边缘设备上,保护敏感信息的同时,提供先进的人工智能能力。目前,Fastino的TLM模型已在金融、医疗、电子商务等多个行业产生影响,助力企业优化运营、提升效率。
在AI模型追求更大规模的背景下,Fastino凭借低成本、高效率的TLM模型,为企业和开发者提供了新的选择。这一创新不仅降低了AI应用的成本,还提升了性能和用户体验,为AI行业的发展注入了新的活力。