安迪·贾西发布Amazon Nova系列模型
亚马逊云科技深夜抛出“王炸”,不仅一口气推出6款大模型,Amazon用于深度学习和生成式AI场景,基于自研芯片的最强EC2实例也来了。
大模型方面,Amazon Nova系列基础模型包括Micro、Lite、Pro、Premier四款。其中,Micro为纯文本模型,128k上下文窗口;Lite和Pro为多模态模型,300k上下文窗口;Premier也为多模态模型,可用于执行复杂的推理任务。亚马逊CEO安迪·贾西(Andy Jassy)在介绍时透露,Micro、Lite和Pro模型已全面开放可用,Premier模型会将于2025年第一季度推出。
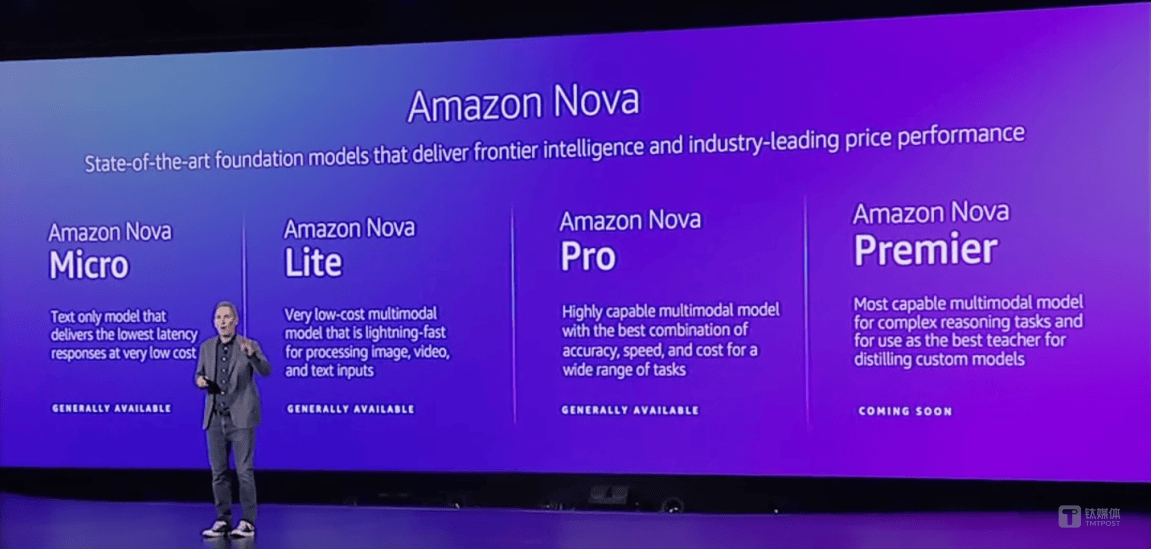
“要是将它(Pro模型)与GPT-4 O进行比较,在20个基准测试中的17个上相等或更优,和Gemini对比,在21个基准测试中的16个上相等或更优。”贾西介绍。他也强调了四款模型的成本效益很高,相较于Amazon Bedrock中的其他领先模型,Nova能便宜大约75%。
四款基础模型不仅集成在Amazon Bedrock中,还与Amazon Bedrock里的所有功能进行了深度整合,任何模型提供商都可以使用并供开发者进行微调。Nova模型还与蒸馏功能整合,可将大模型的智能“转移”到更小的模型中,这些小模型成本效益更高,延迟更低。
另外,贾西也宣布推出了图像生成模型Amazon Nova Canvas及视频生成模型Amazon Nova Real。其中,Amazon Nova Real即将推出可以制作6秒视频的功能,未来几个月内,还会推出能够制作最长2分钟视频的功能。
亚马逊云科技CEO马特·加尔曼(Matt Garman)也在现场宣布,Amazon Bedrock multi-agent collaboration多智能体协作功能同步推出,这意味着Amazon Bedrock智能体能够处理复杂的工作流程。“多个智能体返回了信息,它还能进行协调处理,确保所有这些智能体之间能够有效协作。”马特表示。

马特·加尔曼宣布推出基于Trn2的EC2实例
继AI大模型公司Anthropic宣布下一代Claude模型将在Amazon Project Rainier上进行训练,并产生拥有数十万个Amazon Tranium2 芯片的亚马逊集群之后,马特当地时间12月3日上午便宣布推出由Amazon Trainium2提供支持的Amazon Elastic Compute Cloud (Amazon EC2)实例,新的Trn2 UltraServer、下一代 Trainium3 芯片也同步推出。
“今天,我很高兴地宣布Amazon EC2 Trn2实例正式可用,这些实例由Trainium2芯片提供支持。Amazon EC2 Trn2实例是我们为生成式AI设计的最强大的实例,这都得益于这些完全由亚马逊云科技内部定制构建的处理器。”马特在现场表示。
据钛媒体App了解,基于Amazon Trainium2的Amazon EC2实例,能够训练和部署当今最新的AI模型以及未来的大型语言模型(LLM)和基础模型(FM)。与当前一代基于 GPU 的 EC2 P5e 和 P5en 实例相比,Trn2 实例的性价比提高了 30-40%,并具有 16 个 Trainium2 芯片,可提供 20.8 petaflops 的峰值计算能力,非常适合训练和部署具有数十亿个参数的 LLM。

Amazon Trainium2芯片

Amazon EC2 Trn2实例服务器托架
对于需要更多计算的最大模型,Trn2 UltraServer 允许客户将训练扩展到单个 Trn2 实例的限制之外,从而减少训练时间,加快上市时间,并支持快速迭代以提高模型准确性。Trn2 UltraServer 是一种全新的 EC2 产品,它使用超快的 NeuronLink 互连将四台 Trn2 服务器连接在一起形成一台巨型服务器,可扩展至 83.2 petaflops 的峰值计算能力,将单个实例的计算、内存和联网能力提高四倍,从而能够训练和部署世界上最大的模型。
借助新的 Trn2 UltraServer,客户可以跨 64 个 Trainium2 芯片扩展其生成式 AI 工作负载。对于推理工作负载,客户可以使用 Trn2 UltraServer 来提高生产中万亿参数模型的实时推理性能。
“Trainium2 专为支持最大、最前沿的生成式 AI 工作负载而构建,用于训练和推理,并在 AWS 上提供最佳性价比,”亚马逊云科技计算和网络副总裁 David Brown 说。“随着模型接近数万亿个参数,我们了解客户还需要一种新颖的方法来训练和运行这些庞大的工作负载。新的 Trn2 UltraServer 在 AWS 上提供最快的训练和推理性能,并帮助各种规模的组织以更快的速度和更低的成本训练和部署世界上最大的模型。
以AI大模型公司Anthropic 为例,Claude系列大模型让Anthropic 在全球备受关注。AI大模型公司Anthropic联合创始人兼首席计算官Tom Brown当地时间12月2日宣布,公司旗下下一代的Claude模型将在Project Rainier上进行训练,他表示这将是一个新的亚马逊集群,拥有数十万个Amazon Tranium2 芯片。优化完成后,该集群预计将成为迄今为止世界上最大的 AI 计算集群,可供 Anthropic 构建和部署其未来模型。
“数十万个芯片意味着数百个密集的亿次浮点运算,比我们曾经使用过的任何集群都多五倍以上。这意味着客户将可以更低的价格、更快的速度获得更多的智能。有了 Amazon Tranium2 和 Project Rainier,我们不仅仅是在构建更快的人工智能,还在构建可扩展的、值得信赖的人工智能。”Tom Brown表示。此前一周亚马逊宣布追加对Anthropic的第二笔40亿美元的投资(目前共计亚马逊投资80亿美元),进一步深化两家公司在人工智能领域的合作,加快Anthropic的发展。
同日,亚马逊云科技 也推出了专为满足生成式 AI 工作负载而设计的下一代AI训练芯片Trainium3 芯片,Trainium3 将成为第一款采用 3 纳米工艺节点制造的 Amazon 芯片,为性能、能效和密度设定了新标准。由 Trainium3 提供支持的 UltraServer 的性能预计将比 Trn2 UltraServer 高 4 倍,使客户能够在构建模型时更快地迭代,并在部署模型时提供卓越的实时性能。第一批基于 Trainium3 的实例预计将于 2025 年底推出。(本文首发于,作者 | 秦聪慧)